智谱ZCube组网架构深度技术解析:取消Spine层如何释放15%推理算力
核心结论
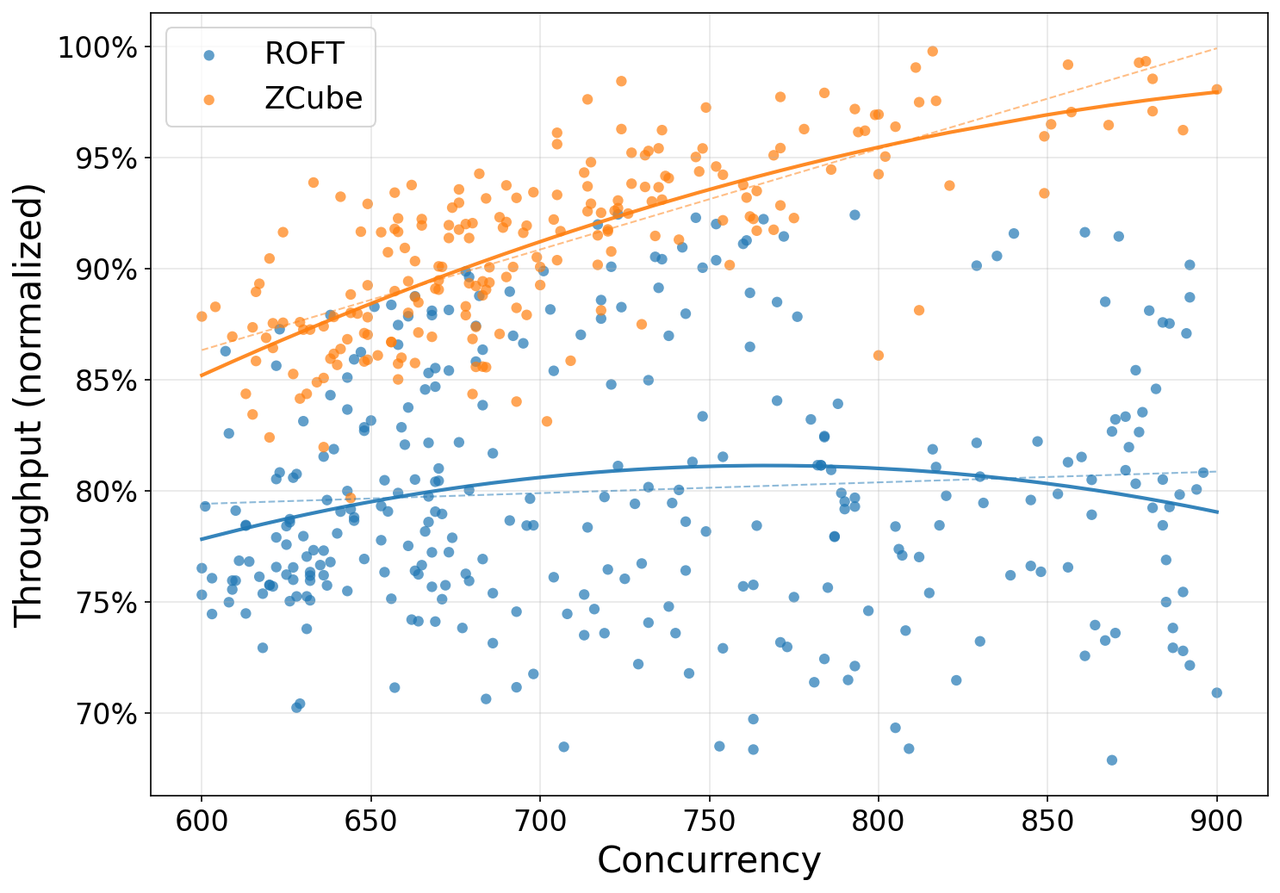
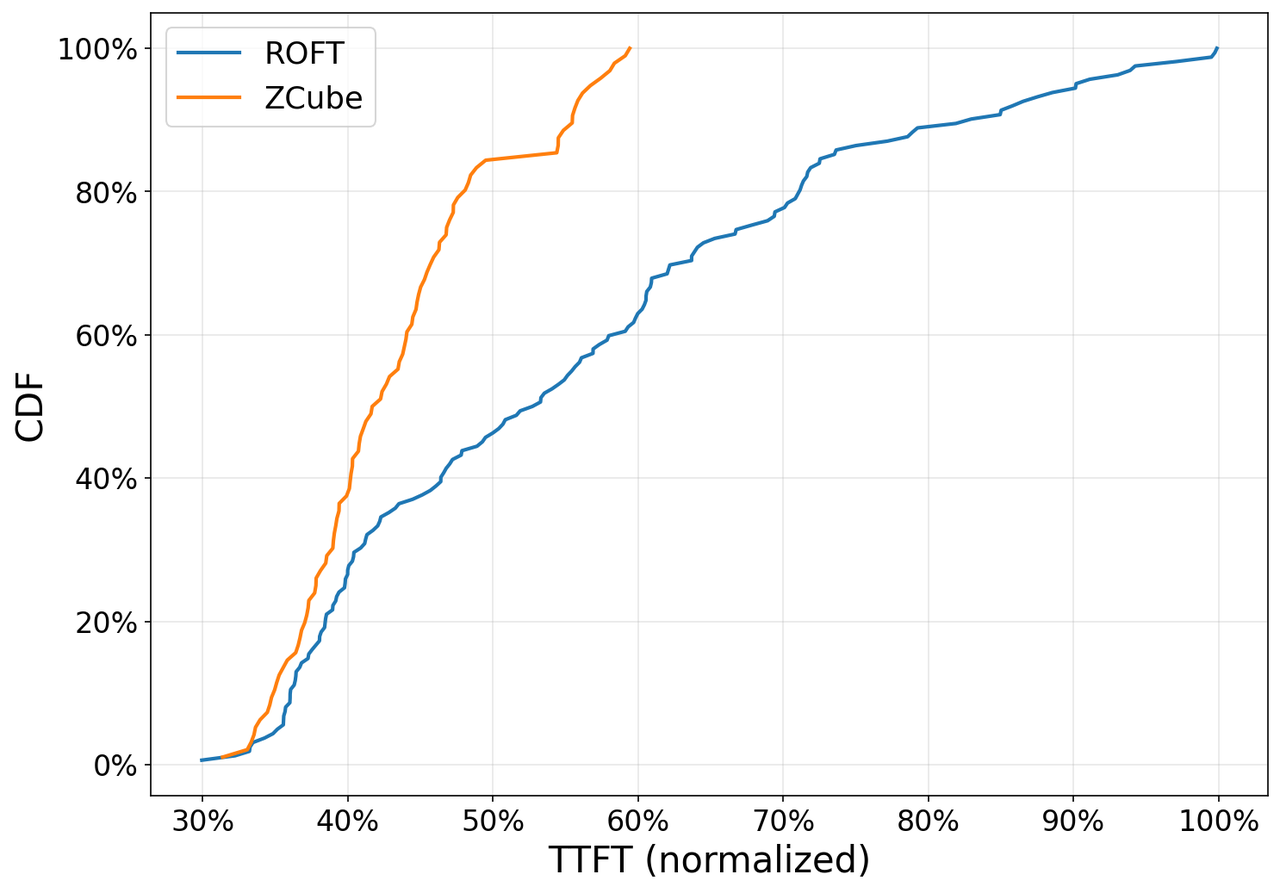
ZCube的核心故事不是"又一种网络优化方案",而是取消Spine层、用二部图扁平互联替代传统Clos分层,从而从根本上解决了大模型推理场景中PD分离带来的流量不对称问题。在GLM-5.1千卡生产集群上,GPU和软件原封不动,仅重构网络拓扑就实现了15%推理吞吐提升和40.6%的TTFT P99降低,同时节省33%交换机与光模块成本[1]。这意味着现有推理集群中约15%的GPU算力被传统架构的低效拓扑"锁死"了。
这一成果发表在ACM SIGCOMM 2025——计算机网络领域最高级别学术会议,评审评价其"significantly change the way we think about and understand networking"(显著改变了整个行业对网络的认知方式)[2]。
一、技术背景:推理网络被忽视的流量不对称
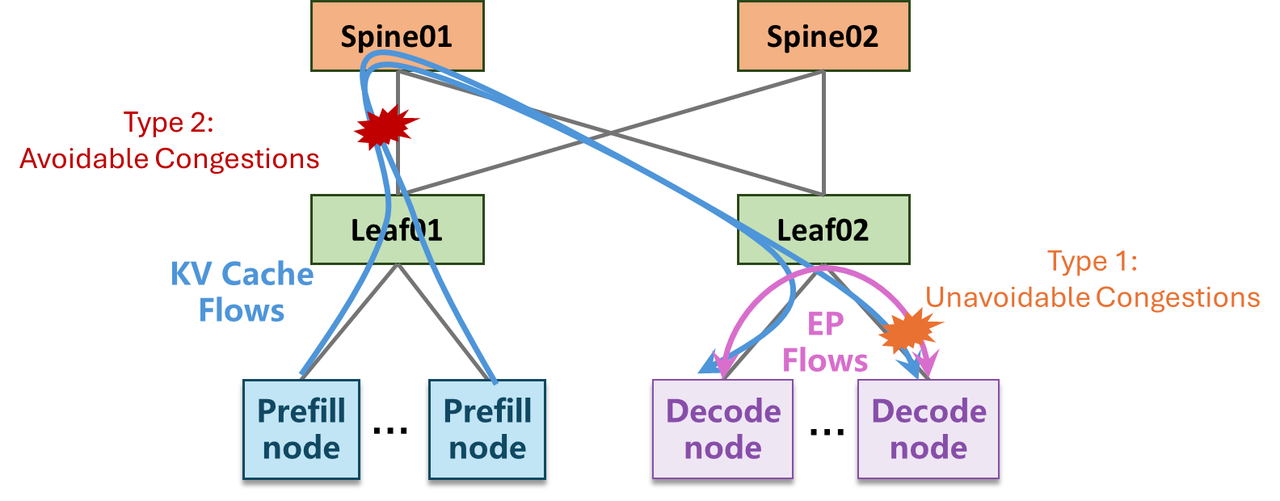
AI网络优化的焦点长期集中在训练场景,但推理的流量模式与训练有本质差异。大模型推理普遍采用PD分离(Prefill-Decode Separation)部署——Prefill节点处理完整的上下文编码,Decode节点做自回归Token生成。这种架构带来的网络流量具有三个传统Clos网络未曾面对的特征:
第一,KV Cache传输量大且极度不均匀。不同请求的上下文长度差异可达数十倍——一个简单问答可能只有几百Token的KV Cache,而一个长文档摘要可能产生数十万Token。这意味着同一时刻,不同Prefill节点向不同Decode节点传输的数据量差异巨大[1]。传统ROFT架构(Rail-Optimized Fat-Tree)的ECMP负载均衡假设流量均匀分布,在推理场景下部分链路过载、部分链路空闲,效率严重损失。
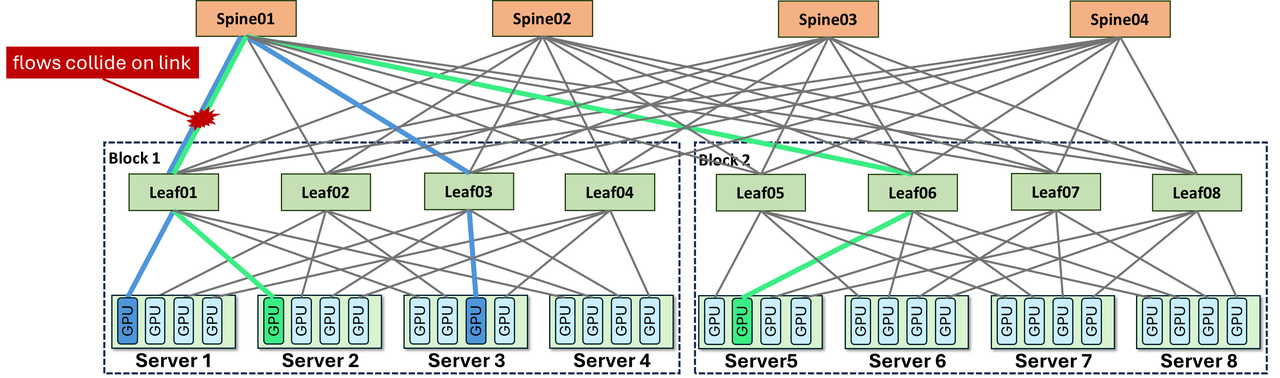
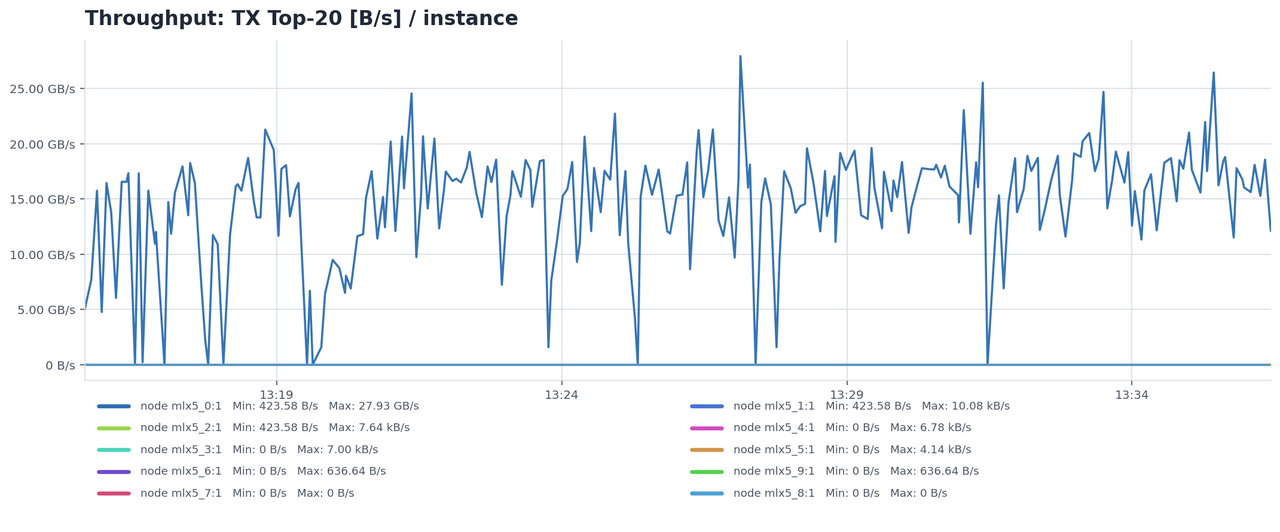
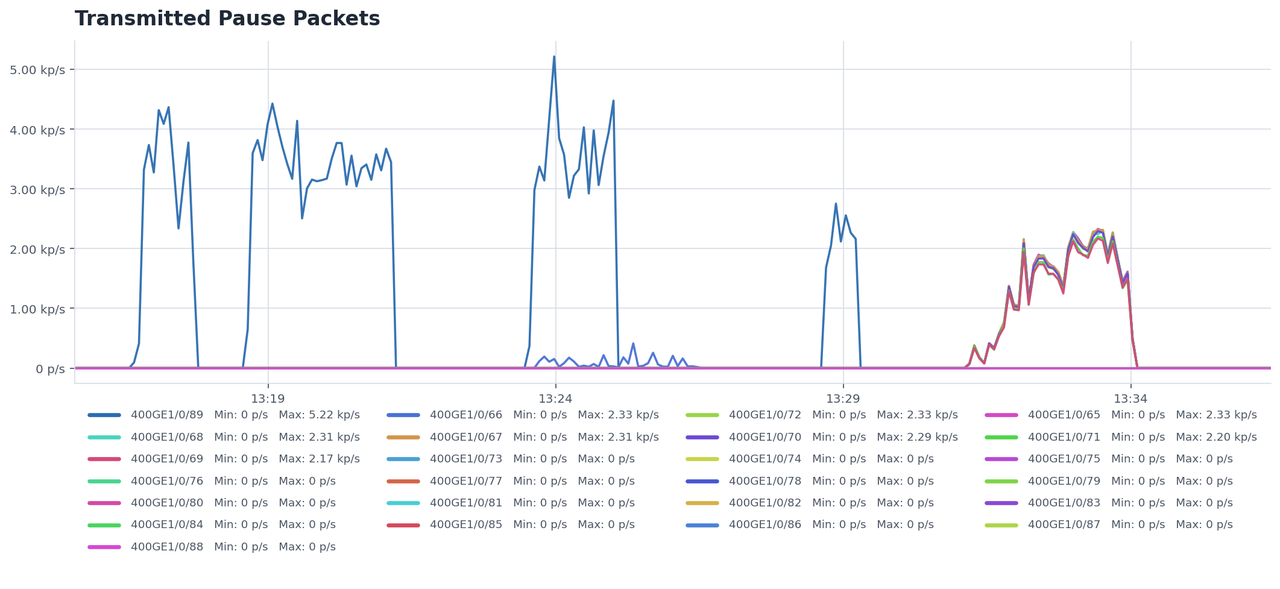
第二,拥塞传导呈热点聚集。由于KV Cache大小不可预测,少数Leaf交换机在特定时刻会变成流量热点。智谱实测发现,PFC(Priority-based Flow Control)反压在这些热点处频繁触发,反压信号沿网络向上游传播,导致不相关的流也被阻塞[1]。这不是带宽不够——而是流量模式与拓扑的"错配"导致了人为的拥塞。
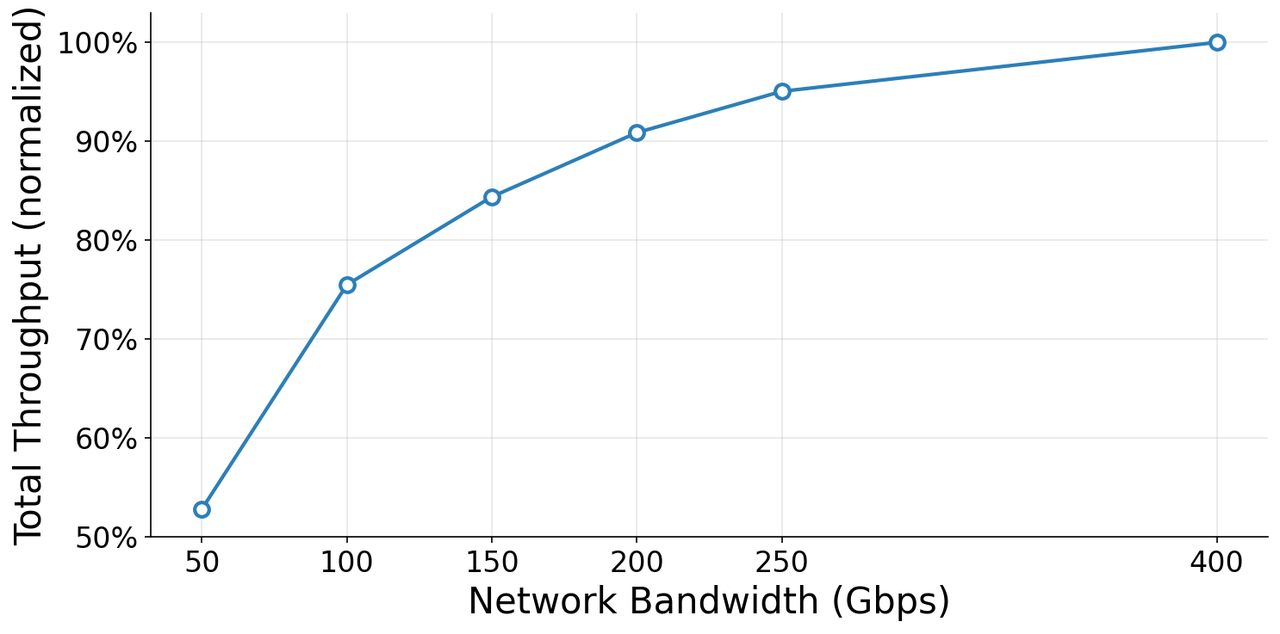
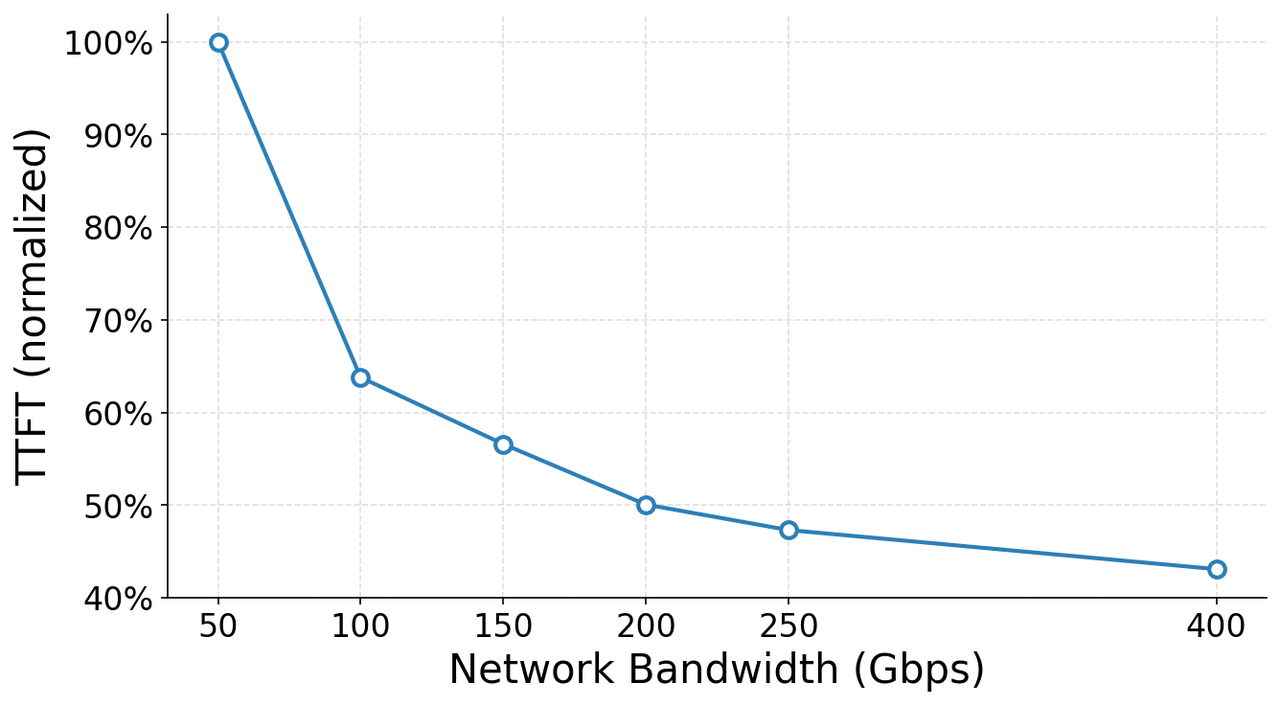
第三,带宽的边际效益显著。智谱做了一个关键的控制变量实验:GPU和软件全部不变,仅将网卡带宽从100Gbps升级到200Gbps,结果是推理吞吐提升19%、TTFT降低22%[1]。这个数据说明推理场景对网络带宽高度敏感——瓶颈确实在网络,而非计算。
实验条件:GPU不变 / 软件不变 / 代码不变,仅升级 100G→200Gbps
结果:推理吞吐 +19%,TTFT -22%[1]
推论:如果带宽翻倍只能换来19%的吞吐提升,说明瓶颈不仅在带宽绝对值,
更在于流量分配效率——即拓扑结构的问题。ZCube的思路正是从拓扑层面解决。
二、ZCube三层架构:扁平化·混合接入·容错
ZCube的技术架构可以拆解为三个紧密关联的层次。核心思想是:取消传统Clos的分层结构,用数学上严格的二部图(Bipartite Graph)互联替代Spine-Leaf两级转发。
2.1 第一层:取消Spine,全网扁平化
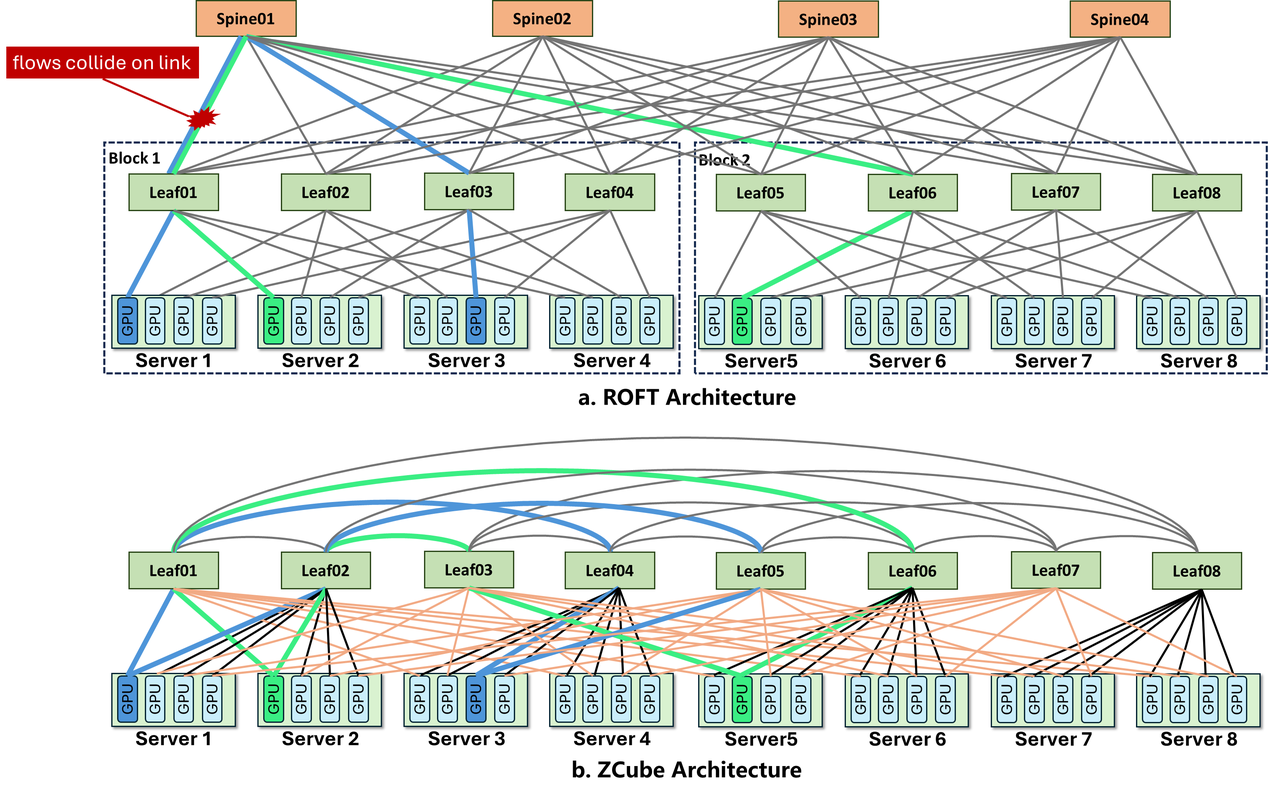
传统两层Clos中,Leaf交换机通过Spine层互联,任意两个不同Leaf下的GPU通信需要3跳(GPU→Leaf→Spine→Leaf→GPU)。ZCube的做法是直接取消Spine层——将所有Leaf交换机按序号分为奇数组和偶数组,两组之间做完全二部图互联:每台奇数交换机与所有偶数交换机直接相连[1]。
网络直径从3跳降到2跳。更重要的是,这种结构在数学上保证了全网任意两张GPU之间有且仅有一条最优路径——不存在ECMP的多路径选择问题,从根本上消除了Hash碰撞导致的负载不均。
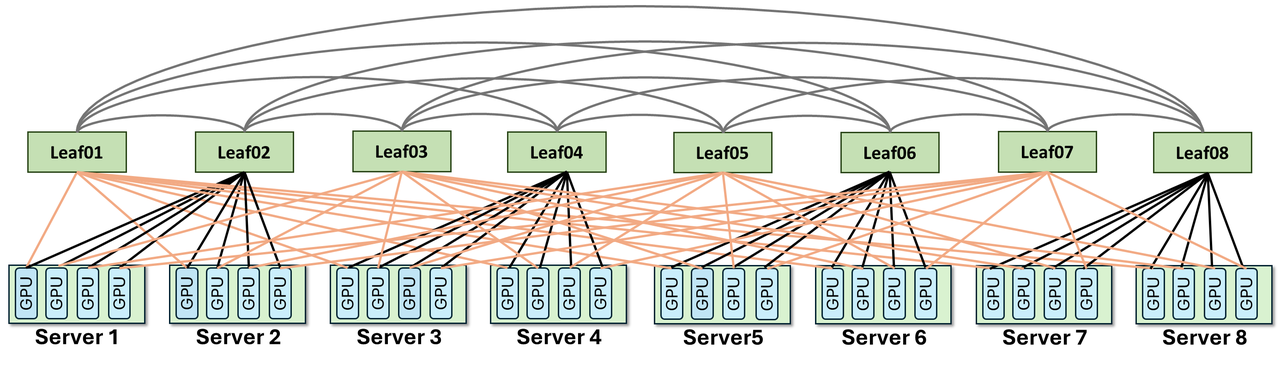
2.2 第二层:单轨+多轨混合接入
现代GPU服务器通常配备双端口网卡。传统做法是两个端口都接到同一个Leaf交换机(单轨接入)或分别接到两个Leaf(多轨接入),两者各有利弊。ZCube引入了单轨+多轨混合接入机制——根据服务器的角色(Prefill vs Decode)和流量特征,动态选择接入方式[1]。
混合接入的核心工程价值在于:结合二部图拓扑,确保全网任意两张GPU之间有且仅有一条最优路径。这条路径是拓扑结构决定的,不需要运行时做ECMP Hash——从结构层面就实现了流量负载均衡。这意味着传统方案中因Hash碰撞导致的"热点Leaf"问题在ZCube中不存在。
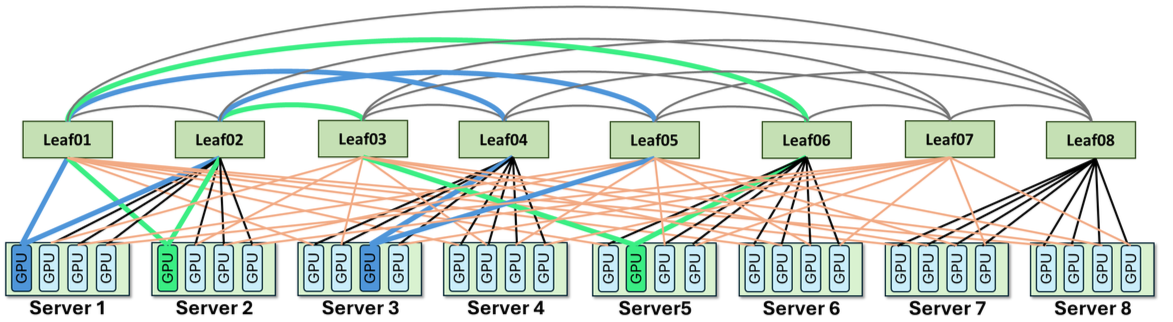
2.3 第三层:更低成本,更强容错
取消Spine层直接减少了约1/3的交换机和光模块数量[1]。但ZCube的容错性反而更好——论文数据显示,GPU对不可达概率比传统双平面Clos低50%以上[1]。
容错性提升的数学直觉:在传统Clos中,Spine交换机是关键中转节点,一台Spine故障会影响所有跨Leaf的通信。ZCube的二部图结构中,每对Leaf之间有直接连接,任意单台Leaf故障只影响其直连的GPU,不会波及其他Leaf对之间的通信路径。故障域更小、更局部化。
三、工程计算验证
ZCube使用 51.2T 交换机(128 × 400Gbps 端口)[1]
二部图中,每台交换机的端口分为:下行连接GPU + 上行连接对组交换机
假设 N 台交换机(N/2 奇数 + N/2 偶数):
每台上行端口数 = N/2(连接所有对组交换机)
每台下行端口数 = 128 - N/2
总GPU网卡数 = N × (128 - N/2)[1]
当 N = 128 时:每台上行 = 64,下行 = 64,总GPU = 128 × 64 = 8,192
当 N = 256 时(需要更高密度或更大交换机):
使用更高容量交换机或多平面部署 → 可扩展至 16,384 块 400Gbps 网卡[1]
更高容量交换机或多平面 → 数万至数十万 GPU
假设GLM-5.1集群规模为 N 个GPU,推理吞吐为 T tokens/s
ZCube提升后:T × 1.15 tokens/s[1]
等效于增加 0.15N 个GPU的推理能力
如果 N = 10,000 GPU → 等效增加 1,500 GPU
万卡规模估算:网络硬件节省 2.1-6.4 亿元[1]
ZCube论文数据:GPU对不可达概率比双平面Clos低50%+[1][2]
直觉解释:传统Clos中,Spine是"咽喉"——一台Spine故障影响所有跨Leaf流量。
ZCube二部图中,Leaf间直接互联,单点故障的爆炸半径更小。
四、与OpenAI MRC的技术路线对比
ZCube和OpenAI MRC几乎在同一时期浮出水面——中美两边都开始在网络层动手。两者代表了AI网络优化的两个正交方向,不是替代关系,而是互补关系。
| 维度 | 智谱ZCube | OpenAI MRC |
|---|---|---|
| 目标场景 | 大规模AI推理 | 大规模AI训练 |
| 核心创新 | 架构层:重构拓扑(扁平化) | 协议层:多路径路由+拥塞控制 |
| 拓扑改变 | 取消Spine,二部图 | 保留多平面+Clos |
| 硬件改动 | 重新布线(物理改造) | 需要MRC网卡 |
| 软件改动 | 无需 | 需要训练框架适配 |
| 性能提升 | +15%吞吐, -40.6% TTFT P99[1] | 实现13万GPU有效训练 |
| 成本节省 | 33%交换机+光模块[1] | ~50-60%交换机总数(vs传统4层) |
| 学术认可 | SIGCOMM 2025 | 暂无学术论文(工程实践) |
两者可叠加:架构层无拥塞 + 协议层强容错
MRC的多平面架构和ZCube的二部图拓扑并不矛盾。在MRC的每个平面内部,可以采用ZCube式的扁平拓扑优化。叠加使用的理论效果:训练场景获得MRC的扩展性和容错性,推理场景获得ZCube的吞吐和延迟优化。两者同在2025年上半年被推到产业台前,不是巧合——当GPU Scaling的边际成本越来越高,网络层成为新的效率杠杆。
从投资回报率看,ZCube的ROI极高——零GPU投入换来15%产出提升。但MRC的价值天花板更高——没有它就做不了超大规模训练。两者解决的是不同层次的问题。详细分析参见:OpenAI MRC协议深度技术解析
五、产业落地与生态
5.1 合作方与分工
ZCube不是智谱一家的成果,而是一个产学研联合体。每个参与方扮演了不同角色:
| 合作方 | 角色 | 核心贡献 |
|---|---|---|
| 清华大学 | 学术研究 | 论文共同作者,网络架构理论,拓扑数学证明 |
| 驭驯网络 | 工程落地 | 完整自动化工具链:机房布局设计、连线正确性校验、配置自动生成与批量下发[1] |
| 字节跳动 | 产业验证 | 论文共同作者,提供大规模网络场景的工程经验和验证环境 |
| 中关村实验室 | 基础研究 | 论文共同作者,国家级网络研究平台支持 |
| 智谱 | 发起方+生产验证 | 提出问题、提供生产集群(GLM-5.1)、论文主要作者 |
值得强调的是驭驯网络的角色。ZCube的部署不是软件升级——是物理改造:布线、IP编址、路由策略、交换机配置全部重新设计[1]。驭驯网络为此开发了完整的自动化工具链,从机房布局设计到连线正确性校验再到配置自动生成与批量下发,将传统需要数周的物理改造压缩到可控周期内。没有这套工具链,ZCube的工程落地难度会高出一个数量级。
5.2 首次生产验证
ZCube在智谱GLM-5.1 coding推理集群上完成了首次生产验证[1]:
- 集群规模:千卡级
- 实验条件:GPU/软件/代码全部不动,只换网络拓扑
- 推理吞吐:+15%
- TTFT P99:-40.6%
- 网络设备成本:-33%(交换机+光模块)
- 运行时长:已稳定运行超两周
- 万卡规模估算:网络硬件节省 2.1-6.4 亿元
这个实验的设计严谨性值得注意:控制了GPU型号、软件版本、推理服务代码三个变量,仅改变网络拓扑。这使得15%的吞吐提升可以完全归因于网络架构的变化,排除了其他干扰因素。在AI系统研究中,这种"单变量控制"的生产级实验非常罕见。
5.3 学术认可:SIGCOMM 2025
ACM SIGCOMM是计算机网络领域的顶级会议,年接收率通常在15-20%。ZCube论文不仅被接收,更获得了审稿人的高度评价——"significantly change the way we think about and understand networking"(显著改变了整个行业对网络的认知方式)[2]。这一评价的分量在于:SIGCOMM审稿人通常对"夸大创新"高度警惕,能获得这种措辞的评语,说明论文在理论贡献和实验验证两个维度都达到了极高标准。
这也是中国AI公司在网络系统领域的标志性突破——在网络系统这一传统上由北美机构主导的学术领域,智谱/清华/驭驯网络的联合工作获得了全球最高级别认可。
5.4 业界评价
- 观察者网:"GPU军备竞赛两年后,网络成为新战场"——准确定位了产业趋势[3]
- 搜狐/新浪/凤凰:"推翻二十年组网逻辑"——标题虽有传播色彩,但技术方向准确[4]
- 同花顺:聚焦"智谱首次实践验证"——资本市场关注的是可复制的商业价值[5]
5.5 GPU适配广度
ZCube不绑定特定GPU。目前已适配英伟达、昇腾、寒武纪、摩尔线程等多家芯片[1]。这一点非常重要——ZCube优化的是网络拓扑而非GPU通信协议,其核心逻辑对GPU型号无依赖。在国产GPU加速迭代的当下,这种架构级的通用性是一个实际的商业优势。
六、工程挑战与局限性
部署是物理改造,不是软件升级。ZCube的实施需要重新布线、重新分配IP地址、重新配置交换机路由策略[1]。这意味着已有的推理集群必须经历一次计划内停机改造。对于7×24小时在线的推理服务,停机窗口的安排本身就是工程挑战。驭驯网络的自动化工具链缓解了这个问题,但没有完全消除。
Incast拥塞仍需拥塞控制。ZCube消除了拓扑层面的流量不均,但无法解决"多对一"的incast问题——当多个Prefill节点同时向同一个Decode节点发送KV Cache时,最后一跳仍然会拥塞[1]。这需要传输层的拥塞控制机制(如DCQCN)来处理,不是拓扑设计能解决的。
还未走出智谱。ZCube目前的生产验证全部在智谱自身的GLM-5.1集群上完成[1]。它是否在其他推理工作负载(如MoE模型、多模态推理)上同样有效?在其他网络设备厂商的交换机上是否可复现?这些问题的答案需要更广泛的第三方验证。
拓扑与推理架构耦合。ZCube的拓扑优化针对PD分离部署设计。当推理架构变化——例如从PD分离切换到Attn-FFN分离,或引入MoE动态路由——最优拓扑可能不同。每次架构迭代都可能需要重新优化物理布线。
七、结论
1. ZCube证明了一个被低估的事实:推理场景的网络效率损失远比想象的大。不是网络不够快,而是传统Clos拓扑与PD分离的流量模式根本不匹配。取消Spine层、用二部图直连替代两级转发,15%的吞吐提升说明过去业界用训练优化的网络架构来跑推理,存在系统性的效率浪费。
2. "不动GPU、不改软件"是ZCube最大的商业优势,也划清了技术边界。零GPU改动意味着极低的部署门槛和极高的ROI,但优化的天花板受限于现有硬件——无法通过协议创新(如MRC的数据包喷射)突破物理极限。ZCube是在现有约束内做到的最好,而非突破约束后的最优。好在两者可以叠加。
3. SIGCOMM 2025是中国AI基础设施研究的里程碑。网络系统领域长期由北美机构主导,智谱/清华/驭驯网络的联合工作获得顶级会议的高度认可,标志着中国AI公司在"从用AI到做AI基础设施"的转型中,开始具备全球一流的技术输出能力。后续观察点:(1) ZCube在非PD分离架构上的适用性;(2) 驭驯网络的商业化进展——能否将ZCube从"智谱专属"变成"行业通用方案";(3) 与MRC等训练网络方案的融合可能性。
参考来源
- [1] ZCube: A New Network Architecture for LLM Inference — 智谱官方技术博客, 2026-05
- [2] OpenAI联合五巨头刚进场,中国团队的答卷已经上线 — 观察者网, 2026-05-21
- [3] 推翻二十年组网逻辑,智谱落地ZCube,让同样的GPU多干15%的活 — 搜狐科技, 2026-05-21
- [4] 智谱首次实践验证下一代AI集群组网架构ZCube — 同花顺, 2026-05-21
- [5] 智谱发布AI Infra新成果:ZCube重构大模型推理网络 — 北京智源研究院, 2026-05-21
- [6] 智谱联合清华等提出ZCube组网架构:大模型推理吞吐提升15% — 站长之家, 2026-05-21
- [7] OpenAI联合五巨头刚进场,中国团队的答卷已经上线 — 凤凰网, 2026-05-21
- [8] 智谱落地ZCube,大模型厂商同步押注下一代网络架构 — 财经号, 2026-05-21